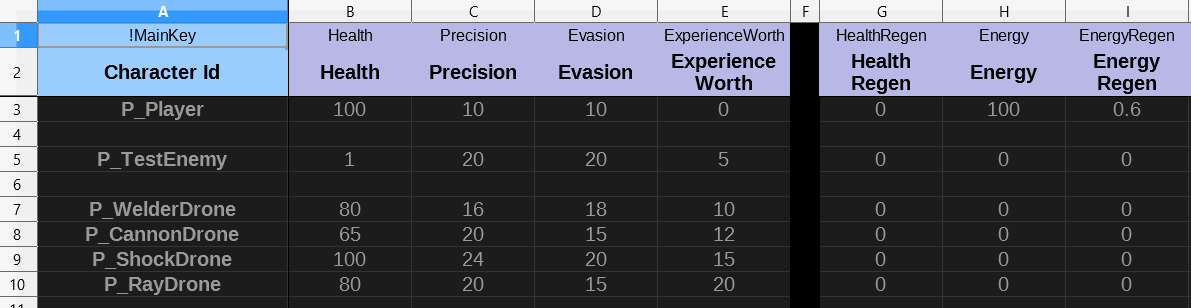
Dark theme for the win!
Let’s get straight to the point!
Spreadsheets are excellent for setting and tweaking static game data. In my experience, nothing comes even close to the speed and convenience of spreadsheets, with all the modern editing capabilities. JSON, YAML, TOML, XML, SQL, they all fade before the king!
Why
Because:
- Baking game data into source code is outright bad! It’s typically hard to find any specific value and requires recompilation on every change.
- XML and JSON are verbose and it’s difficult to change multiple related values quickly. Say, you need to tune down the health of all enemies. Oh well…
- Full-blown database systems like MySQL are too heavy to set up and maintain, to my liking.
How
We’re using LibreOffice Calc (free alternative to MS Excel) to create sheets of data. All kinds of data. Enemy health, skill cooldowns, damage values, traits, attributes, you name it. The sheet is a perfect fit for this kind of tabular data — related keys of many elements. To update the game with the tweaked values, we simply export all sheets into CSV files that the game can read.
-
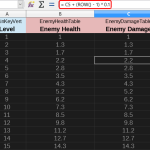
- Sheet formulas are perfect for scaling values like enemy damage.

-
- Sheets don’t have to be dull. Colors for the win!

Sheets
The sheet is typically set up like this:
- The column marked with
!MainKeyis reserved for identification of the element. The game creates a dictionary entry for each cell in this column.!MainKeyVertis used for vertical sheets — the game processes them with a slight difference. - The first row are the keys. The game reads these keys and assigns the column entries to the given main key entry.
- Most keys are standard, meaning that they repeat many times for many different game objects / prefabs / actors.
- Unique keys are marked with
!, and the game reads them in-line along with the value. This is the best we came up with for non-tabular data, e.g. keys that never or seldom repeat. If you have a unique skill that does something that no other skill does, the key for the value of that action is most likely going to be unique. So this is for that case.
- The second row are nice names so it’s easy to understand what is what at a glance. This is ignored by the game. It’s only presentational.
Automation
As I mentioned, we save all the sheets from the doc into CSV files, so the game can read the precious data. But, it would be horrid to manually re-export every sheet to a CSV file every time you changed a value. LibreOffice script to the rescue! It exports all the sheets to CSV files whenever we save the doc. The game then simply loads all these CSV files into various static dictionaries. Automation for the win!
Other parts (characters, skills, attribute banks…) then simply read the values from the proper dictionary by a key they get from the prefab name (or whatever suits us).
The loader class can be as simple as this:
using UnityEngine;
using UnityEngine.Assertions;
using System;
using System.Collections.Generic;
// ----------------------------------------------------------------
public class VapCsvReader
{
/// <summary>
/// Delimiter used for parsing CSV files.
/// </summary>
private const char CsvDelimiter = '\t';
/// <summary>
/// We ignore columns marked with this key. They are only there to improve editing experience & convenience.
/// </summary>
private const string PresentationKey = "-";
/// <summary>
/// We treat columns marked with this key as key-value pairs, parsing them as such. Used for ids.
/// </summary>
private const string CustomDataKey = "!";
/// <summary>
/// Delimiter for parsing cells that themselves contain key-value pairs.
/// </summary>
private const char CustomDataDelimiter = ':';
private static bool verticalMode;
// ----------------------------------------------------------------
/// <summary>
/// Reads a CSV file into a dictionary.
/// </summary>
/// <param name="resourcePath">Path to the CSV file.</param>
/// <returns>A dictionary of strings and list of strings.</returns>
public static Dictionary<string, List<string>> ReadCsv(string resourcePath)
{
// Get text asset.
var text = Resources.Load(resourcePath) as TextAsset;
Assert.IsNotNull(text, string.Format("{0} not found!", resourcePath));
// Create dict.
var dict = new Dictionary<string, List<string>>();
// Get rows.
var rows = text.text.Split(new[] { Environment.NewLine }, StringSplitOptions.None);
// Iterate, skipping first 2 rows (1st = keys, 2nd = presentation only).
for (var i = 2; i < rows.Length; i++)
{
// Get all cells of the row.
var cells = rows[i].Split(CsvDelimiter);
// First cell is an id.
var id = cells[0];
// Or it ain't. :) In that case, carry on.
if (id == string.Empty)
continue;
// Create a list.
var list = new List<string>();
// Add it to the dict.
dict.Add(id, list);
// Go thru the cells, skipping the first.
for (var n = 1; n < cells.Length; n++)
{
// Add a cell's content to the list.
list.Add(cells[n]);
}
}
return dict;
}
// ----------------------------------------------------------------
/// <summary>
/// Includes data loaded from a CSV file into the given Dictionary.
/// </summary>
/// <param name="resourcePath">Path to the CSV file.</param>
/// <param name="dict">The Dictionary to include into.</param>
public static void IncludeCsvIntoDict(string resourcePath, Dictionary<string, object> dict)
{
// Set default mode.
verticalMode = false;
// Get text asset.
var text = Resources.Load(resourcePath) as TextAsset;
// Get rows.
var rows = text.text.Split(new[] { Environment.NewLine }, StringSplitOptions.None);
// The very first row is reserved for keys, so read that.
var keys = rows[0].Split(CsvDelimiter);
// Find the key which we'll use as the base for inclusion.
var baseKeyIndex = Array.IndexOf(keys, "!MainKey");
if (baseKeyIndex == -1)
{
baseKeyIndex = Array.IndexOf(keys, "!MainKeyVert");
Assert.IsTrue(baseKeyIndex != -1, string.Format("{0} is missing a !MainKey or !MainKeyVert entry!", resourcePath));
verticalMode = true;
}
// Iterate, skipping first 2 rows (1st = keys, 2nd = presentation only).
for (var i = 2; i < rows.Length; i++)
{
// Get a row.
var r = rows[i];
// Get all cells of the row.
var cells = r.Split(CsvDelimiter);
// Determine the base key.
var baseKey = cells[baseKeyIndex];
// If the cell with the base key index is empty, nothing to do here. Skip the row.
if (baseKey == string.Empty)
continue;
// Go thru keys.
for (var n = 0; n < keys.Length; n++)
{
// Get a key.
var key = keys[n];
// Skip presentational keys and the base key index. Got nuttin' to do with those.
if (key == PresentationKey || n == baseKeyIndex)
continue;
// Get the cell content with the key's index.
var cell = cells[n];
// Empty cells don't wanna be touched. Skip 'em.
if (cell == string.Empty)
continue;
// If the key tells us to parse the cell as a key-value pair...
if (key == CustomDataKey)
{
Assert.IsTrue(cell.Contains(CustomDataDelimiter.ToString()), string.Format("{0} error in file {1}: Custom data must have '{2}' as key-value delimiter at row {3}, column {4}", typeof(VapCsvReader), resourcePath, CustomDataDelimiter, i + 1, n + 1));
// Split the cell by the custom data delimiter.
var data = cell.Split(CustomDataDelimiter);
// Set the key to the left side.
key = data[0].Trim();
// Set the cell content to the right side.
cell = data[1].Trim();
}
// Construct our final full key, so longed for for countless ages across many continents.
var fullKey = baseKey + "." + key;
// These verticals gotta be special, hm?
if (verticalMode)
{
fullKey = key + "." + baseKey;
}
// Bitch the fuck out of it when trying to add keys that're already there!
Assert.IsTrue(!dict.ContainsKey(fullKey), string.Format("What the hell is wrong witchu' son? Somebody already slapped key '{0}' onto the dictionary! So either you or them is pretty misled, dude.", fullKey));
// Add the key.
dict.Add(fullKey, cell);
// Fix any missing keys in the dictionary along the path to the full key. This is for other classes to be able to ask whether some key even exists before doing more work.
// IMPORTANT: Me loves 'while trues'!
while (true)
{
// Get the index of the dot.
var dotidx = fullKey.LastIndexOf('.');
// If there ain't any, get the horse outta here.
if (dotidx == -1)
break;
// Chop the full key up to the last dot (exclusive).
fullKey = fullKey.Substring(0, dotidx);
// Now add it to the dict if it ain't there already.
if (!dict.ContainsKey(fullKey))
{
dict.Add(fullKey, null);
}
// And now, the bracket slide...
}
}
}
}
}
If you don’t feel like writing your own or using ours, there are good libs out there:
We also have a neat class to manage the static dictionaries, to help retrieve values from it, but I’ll leave that to you to come up with. Don’t wanna get spoiled too hard, right? 😉

Unique keys go into the cell as a key-value pair.
Conclusion
We were using our own, simplified implementation of YAML for all game data, but that became a chore to maintain. The number of elements just grew too much.
Once we created this sheet data flow, it’s become a breeze to not only tweak, but also find and understand all the values at a glance. Shorter iteration times (tweak -> test) help a ton for any project bigger than Tetris! And besides, attentive readers noticed we had three ‘for the wins’ in the article, so it has to be cool! 🙂